
In today's busy market, companies compete more with customer experience than with their products. The problem is that many fail to understand what “good customer experience” really means.
Many might think that to satisfy their customers, they need to develop the best and most competitive products. However, this isn't necessarily the case.
What the customers need is a smooth, effortless experience. That's what makes them satisfied.
A study by HBR of over 75,000 companies showed that impressing customers has less impact than solving problems quickly and making things easy to use.
You need to talk to your customers to find out what solutions they are looking for and when they encounter friction. The best way to do this is to use customer surveys.
But there's a catch. You don't want the surveys to become another friction point in customer experience. You must make them short and sweet but still gather the right data to improve your business.
Enter the Net Promoter Score (NPS) survey—the easiest way to gauge customer loyalty and predict company growth.
Tl;dr
The Net Promoter Score (NPS) is a way of measuring how satisfied customers are with your products but also with
- your customer service
- ease of interaction with you
- the overall customer experience
It is best measured with a survey that contains two questions—the NPS question and a customized follow-up.
Even though it asks about the likelihood of respondents recommending your brand, it is really asking about whether they think your brand is worth recommending. Therefore, it actually gauges how happy they are with their experience with you.
What is the Net Promoter Score (NPS)?
Net Promoter Score® (NPS) is a popular CX (customer experience) metric. It measures customer sentiment toward the brand based on the answer to one question:
“How likely are you to recommend [company X] to a friend or colleague?”
On a scale from 0 to 10. The easiest way to get that data is by using a survey.
Although seemingly simple, NPS is a complex customer experience metric that will help you gauge the following:
- Customer satisfaction levels
- Growth potential
- Customer experience quality
- Brand perception
- Organizational performance
- Referral potential
Net Promoter Score (NPS) survey questions
NPS system allows you to see your company through the customers' eyes without the complexity of traditional surveys. Instead of going through lengthy questionnaires, customers are asked:
How likely would you recommend [company X] to a friend or colleague?
Why this particular question? In 2003, Frederick F. Reichheld introduced the concept of NPS in his article "The One Number You Need to Grow."
Reichheld spent two years studying this. He found that the likelihood of people recommending a company to others is strongly linked to how fast that company grows compared to its competitors. This question was a better predictor of growth than others he examined during his study.
But don't play down the power of follow-up open-ended questions. As former Director of Product at LinkedIn, Sachin Rekhi rightly argues:
“The most actionable part of the NPS survey is categorizing the open-ended verbatim insights from promoters & detractors.”
When running an NPS survey, ask a follow-up question based on the respondent's initial answer. You can:
- Ask the promoters what they enjoy the most about your product;
- Ask the detractors what's the leading cause of their frustrations;
- Ask all respondents to tell you what they'd add to your product if they could.
This is easy with appropriate skip logic. It lets you create different paths for the respondents by skipping questions and segmenting users based on previous answers.
Skip logic allows you to ask the smallest number of highly relevant questions and create a personalized experience. You can ask different follow-up questions to all three respondent groups (promoters, detractors, and passives).
Skip logic lets you create a personalized experience for each respondent, shorten your survey, and collect only relevant answers. It also helps you categorize the responses better and gain more precise insights to act on immediately.
Skip logic is just a drop in the bucket when it comes to Survicate's broad survey logic. Our software provides sophisticated survey logic for all question types (even open-text responses). You can use it in your email, link, website, and in-product surveys. It is the most advanced survey logic out there.
💡 YOU MAY ALSO BE INTERESTED IN: NPS with follow-up questions survey template
How to calculate the Net Promoter Score (NPS)?
For the Net Promoter Score calculation, you need to subtract the percentage of detractors from the percentage of promoters.
NPS = % Promoters – % Detractors
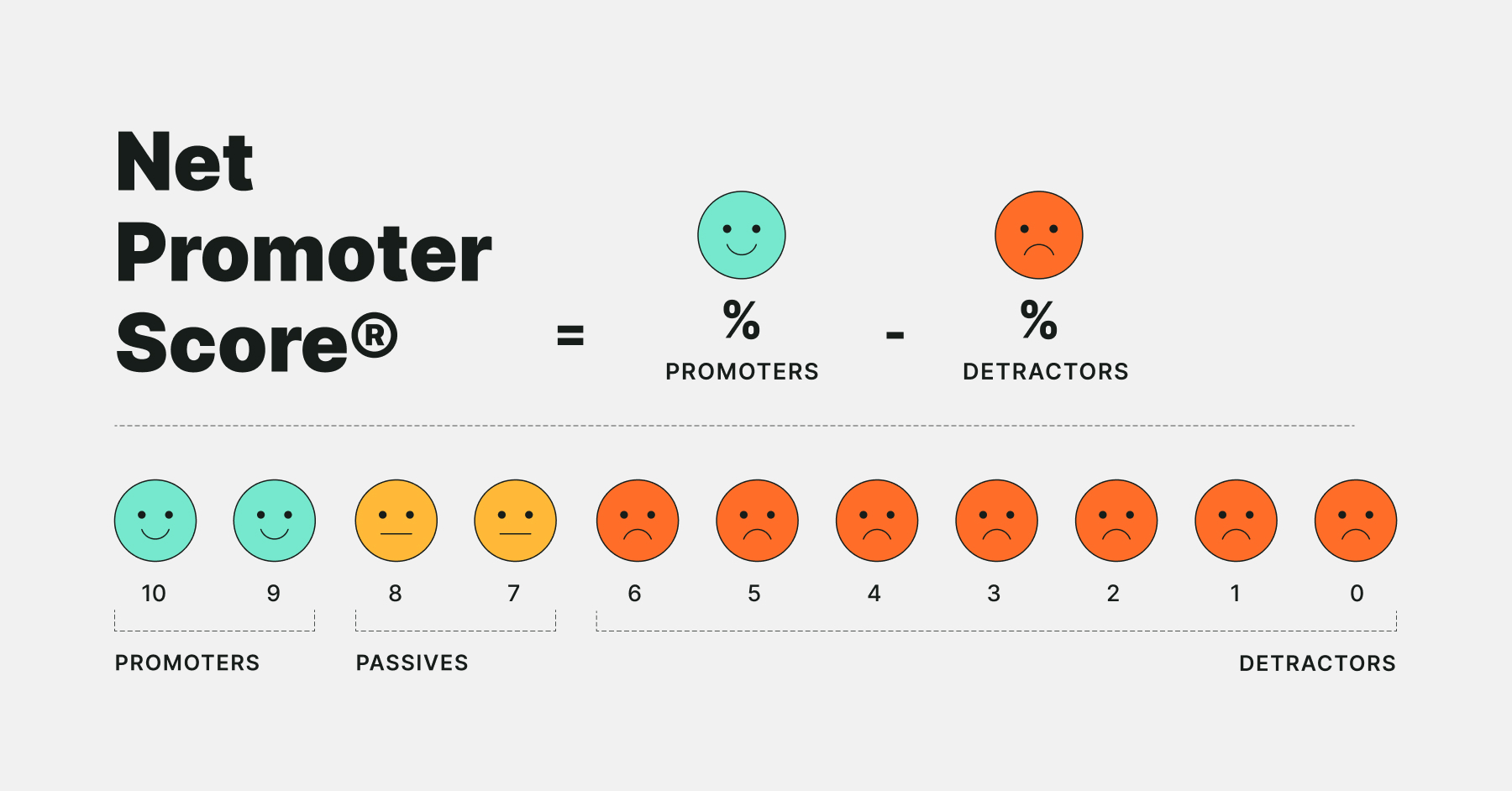
It's important to remember that the Net Promoter Score is not a percentage but an integer. That is, a number between -100 (if every respondent is a detractor) and +100 (if every respondent is a promoter).
For example, if you have 35% promoters and 20% detractors, the NPS will be +15.
Check out our free NPS calculator and experiment.

What are NPS promoters?
NPS promoters are respondents who chose scores 9 and 10. They're your most loyal customers. Promoters are repeat customers who can help your company grow by acting as brand ambassadors and spreading the word to others.
What are NPS passives?
Passives are the respondents who chose scores of 7 to 8. They are typically satisfied but uninvolved and easy to win over by your competition.
What are NPS detractors?
Detractors are respondents giving a 0-6 score. Detractors are unsatisfied customers who won't buy from you again. They're likely to switch to your competition and share their negative opinions, which might drive potential customers away.
What is a good Net Promoter Score? NPS Benchmarks
There are no universal NPS benchmarks. Which Net Promoter Score is “good” or “bad” varies from industry to industry and from company to company.
It is best to measure your NPS regularly and look for patterns. If your Net Promoter Score is improving, you are going in the right direction. If your NPS is declining, you should make some changes.
At Survicate, we investigated our customers' average Net Promoter Scores to create a comprehensive NPS benchmark report. Here's what the benchmarks look like for our client base:
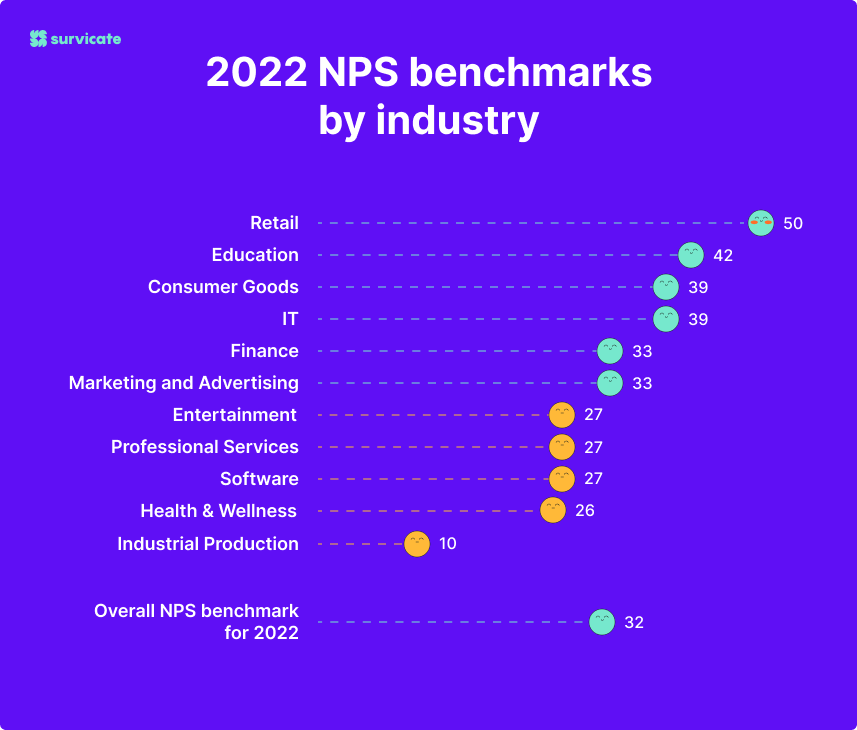
As you can see, the NPS statistics vary from industry to industry. To uncover what "good NPS score" means for your business, you can also stack it against your competitors. Maybe you're lagging, doing just fine, or your extra high NPS can become your USP (Unique Selling Proposition).
Consider any NPS above 50 as extremely good. However, even companies with top NPS scores (approximately 70) still have room for improvement.
Any result greater than 0 is satisfactory—your customers are more satisfied than dissatisfied.
Why the net promoter system works
Firstly, it's because of the ways our brains are wired. NPS puts the customer in the center of the survey. Notice it's “How likely are you to recommend [company X] to a friend or colleague?” and not: “How well did [company X] do its job?”
People spend approximately 30% – 40% of their conversations talking about themselves. According to Harvard University research, they get a “biochemical buzz from self-disclosure.”
Secondly, NPS is powerful because it's simple. The shorter the survey, the more actionable it is. The results are easy to interpret and people are more eager to participate. Long surveys tend to yield low response rates and volatile results.
Furthermore, NPS introduces a data-driven approach to qualitative customer feedback. It's consumer-centric and organized, allowing you to see the full picture and take action easily.
Why is the Net Promoter Score important?
Net Promoter Score is important because it helps you discover the strength of your brand and predict your growth rate. A high NPS suggests your customers are loyal and likely to recommend your company. And word of mouth is an invaluable form of marketing.
NPS feedback has a very positive effort-to-gain ratio. The NPS question feels easy to respondents and requires little time to answer. At the same time, the results allow you to drive complex conclusions.
However, to grow your business, you need more than just NPS. One condition is that you must act on the insights gathered in the process and remove the guesswork from your business decisions.
As Nichole Elizabeth DeMeré argues, you should:
“Think of NPS, or Net Promoter Score, like rocket fuel. If you leave it alone, it won't do much. But when you load it into a responsive, proactive, customer-driven company, blast off.”
NPS can have many benefits both for the company and the respondent:
- The system is intuitive and straightforward to implement, even for non-technical staff.
- It's easy to comprehend and share across teams and departments.
- You don't have to explain it to respondents.
- It's an operating management tool. Because the results are actionable, they reflect the strengths and weaknesses of any team faster than other KPIs do.
- NPS has a high response rate and is time-efficient for both the responder and the surveying party.
- It's comparable over time and easy to benchmark. As long as you keep the survey contents intact, you can accurately compare results.
- It's actionable. Although reviewing the respondents' comments takes a lot of manual work, they are an absolute goldmine of customer insights. Sort answers given by survey participants to detect the strengths and weaknesses of your product or service.
- Finally, NPS allows you to identify customers at risk of churning so you can intervene and help them.
Ideally, NPS adds to the performance, acquisition, and monetization KPIs. Do not treat it as a substitute.
How to collect Net Promoter Score (NPS) data
To measure Net Promoter Score, you must first set up an NPS survey to gather customer feedback. The easiest way to do it is with the help of NPS software like Survicate.
Survicate allows you to run multi-channel NPS surveys. Use it to reach your audience via email, on your website, in your product, or in your mobile app. After setting up a free account, you need just a few clicks to collect your feedback immediately.
When all the responses and data in the result panel, you can quickly analyze the results and take action. This will help you reduce churn and drive business growth.
Your survey type should depend on your customers' preferred channels, your business model, and the kind of feedback you're after.
Relationship vs transactional NPS surveys
There are two approaches to your company's NPS score: transactional and relationship NPS surveys
- A relationship NPS survey concerns your customers' overall attitude towards your company. Use it to measure customer loyalty and satisfaction and build yearly KPIs based on your NPS benchmarks. It's best to run a relationship NPS survey at regular intervals.
- A transactional NPS survey gathers feedback right after a customer interaction with your company. It concerns a specific touchpoint—a chat with customer support or a product purchase. A transactional survey will help you get clear-cut business insights and quickly discover your strengths and weaknesses.
NPS email surveys
Email surveys use hyperlinks in the email HTML code. You can embed the first question in the email body.
You can send email surveys from regular inboxes or mailing software. To get started faster, use email templates in CRMs like HubSpot or via marketing automation software like Intercom. You shouldn't edit the NPS survey too much anyway.
NPS email surveys are helpful when you want to question your customers after they've performed a specific activity. For example, a post-purchase survey.
A good NPS survey tool
- records answers
- minimizes manual work
- makes data easy to analyze and compare over time
- stacks results across different customer segments
Email surveys have a high response rate because they require very little time and effort on the respondent's side. They also don't need any code to run, so they're super simple to implement.
Targeted website surveys
Website surveys can reach more respondents than email surveys because they don't require client data. You can choose between on-page or pop-up surveys.
The strength of website surveys lies in targeting. You can show your surveys only to specific customer segments based on their visit frequency, seen pages, or how they reached your site. You can also set up particular triggers. For example, only show the surveys after the clients make a purchase or when they're about to exit your site.
Due to their discreet character, website surveys have high response rates (up to 58%). You can also customize their appearance and position (left, right, bottom, top, or in the center of the screen).
How to read your NPS score? NPS analysis
The NPS score is an indicator of your future growth or decline. Simply put, you're in the clear if your score is rising. If it's dropping—you have some work to do.
However, obtaining only the numerical score from your NPS surveys wastes resources and customer engagement.
Here are four ideas for reading and analyzing your Net Promoter Score survey results.
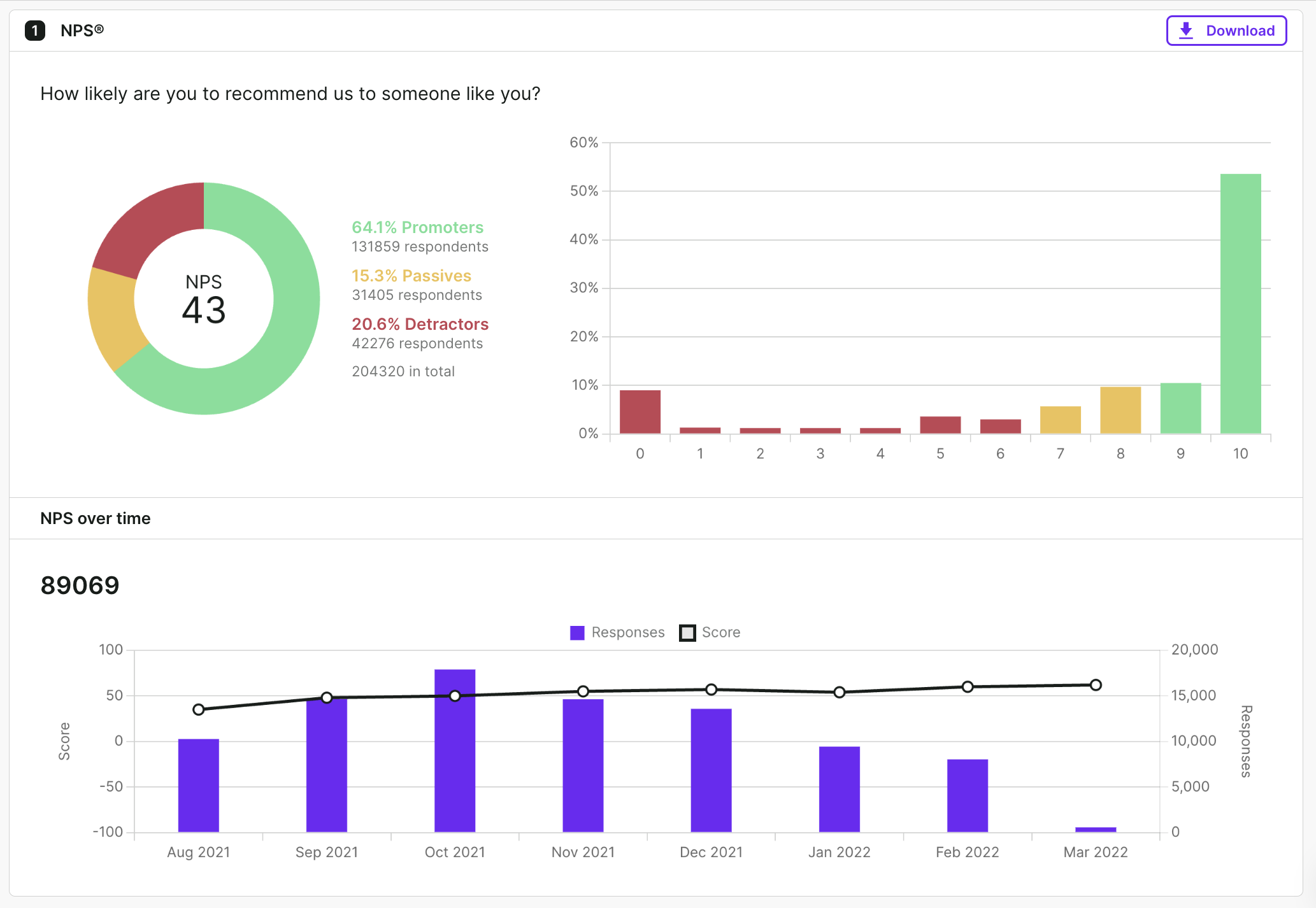
1. Check the response breakdown
NPS is all about the score you get by subtracting the percentage of detractors from the percentage of promoters.
However, you can get valuable insights from the individual survey score distribution. Just think about it: a detractor who chose “1” will be much different from the one who chose “6.”
Create a breakdown of how many times your respondents picked each score. If you use Survicate, you will see it automatically in the “Results” section.
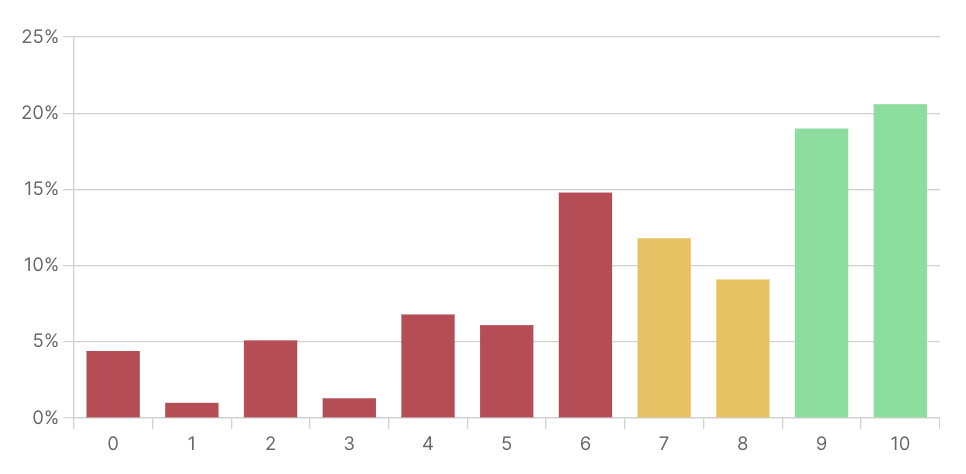
Here are a few things you should pay attention to:
- Is your audience polarized? Or do you have a lot of lukewarm users? This information will help you decide whether to focus on putting down fires or activating the undecided.
- What does the detractor breakdown look like? Are the answers split evenly between each score? Or, does your audience gravitate towards 1 or 6? Maybe it's easier than you thought to turn your detractors into promoters, or at least passive.
- Are there a lot of zeros and ones? Try to act on the negative feedback and re-think your product-market fit.
- Do you have many happy customers who chose 9 or 10? If the answer is “yes,“ target them to get public reviews.
- Is the majority of respondents passive? Devote your efforts to turning them into promoters.
These insights will help you find and prioritize growth opportunities.
2. Look for patterns in open-ended question responses
Every NPS survey should include open-ended questions. These ask your clients to explain their choices and maybe leave a suggestion.
Respond to the survey below to see how the open-ended question adds to the numerical NPS question:
It's unlikely you'll bring every suggestion to life, but you should look for repetitive requests or complaints. If you notice a pattern, it’s time to act! Try to add the features your clients ask for or fix the elements that frustrate them.
3. Monitor the responses based on customer segments
If you're not doing customer segmentation yet, you should start now. By categorizing your clients into different groups, you can gather even more accurate insights and run targeted campaigns.
Track the answer distribution across different customer segments and look for patterns.
For example, if you measure NPS for a B2B SaaS, you might find that your biggest promoters are high-level marketers, while most of your detractors are tech leaders.
You can then investigate the reasons behind their opinions to understand your customers better and improve your product.
To determine the respondent's segment, you can ask additional demographic questions in your survey.
But it's better to gather this data automatically. If you use Survicate, integrate it with your CRM to get instant client information.
But it’s better to gather this data automatically. If you use Survicate, integrate it with your CRM to get instant client information.
4. Track results over time
Monitor how your NPS score changes over time to keep an eye on your customer experience program. This will help better predict your growth.
Comparing responses over time will help you find your benchmarks and discover fluctuations. Once you gather a lot of data, you can investigate the reasons for your gains and losses and take action.
It's also a good idea to supplement your NPS results with CSAT and CES survey data.
Net Promoter Score best practices
Do you want to get the most out of measuring the Net Promoter Score? Here are a few NPS survey best practices.
1. Turn feedback into action
Measuring NPS is not enough to grow your company. You must also take action based on your findings.
Observe NPS score fluctuations and act whenever you see big drops. Categorize positive and negative feedback to discover underlying issues.
Close the feedback loop with your customers. Always let your customers know you listen to them and act on their suggestions. This is the only way to create a customer-centric company and boost customer experience.

💡Real-life example: Hitta
Hitta, a Swedish search engine that specializes in providing comprehensive information about individuals, businesses, and locations, uncovered weaknesses in its onboarding process while analyzing the NPS responses.
When we started collecting feedback from our customers, we already knew there was space for improvement in our processes. Our clients showed us where to begin.
Alice Samuelsson, Product Manager at Hitta
To address this, the company redesigned its onboarding experience to more quickly identify unmet customer expectations and potential issues. Just three months after implementing the changes, Hitta achieved a remarkable 35% improvement in its NPS score.
2. Leverage your promoters
Many companies focus on the detractors and devote all their energy to fixing their shortcomings. That's a mistake.
Your promoters have explicitly told you they will likely recommend your company—so why not try to make it happen? Depending on the nature of your business, you can ask your promoters to
- leave a review
- write a testimonial
- take part in a referral program
💡Real-life example: Pranamat
Pranamat used Survicate's conditional logic to ask the NPS promoters for an online review. Results ? The company improved its Facebook rating to 4,9/5.
The most important and interesting thing for us is that we see growth in our affiliate network because we automatically invite all the promoters to become our ambassadors and promote our product. We also ask them to leave reviews on Facebook if there is a good net promoter score.
Aleksejs Krūmiņš, Head of Growth Marketing at Pranamat
3. Measure regularly
You can only trust your NPS score if you continue measuring. You'll get in-the-moment insights, track unexplained variations, and see how your customers feel about the changes you make.
Re-run the NPS survey regularly (once or twice a year—or more often if you have a big customer base) and compare the numbers.
💡Real-life example: wetter.com
wetter.com, a leading weather forecasting platform, uses its NPS to establish a baseline for monitoring trends and evaluating the impact of updates over time. By sending surveys monthly, they can observe how satisfaction levels shift across different seasons and make data-driven adjustments accordingly.
You need to start somewhere and then see the baseline. Our business depends on the weather, so our users are probably less satisfied on rainy days. It’s quite the opposite when it’s sunny. We can see this in the surveys, but we needed a year or two to establish a baseline. Now we know it’s a normal trend.
Falco Kübler, Senior Product Owner at wetter.com
4. Run NPS surveys at the right time and place
Don't attack your customers with questions at random moments. Integrate your NPS surveys with the customer journey.
Show the survey after meaningful interactions with your company. Also, choose clients who have already had a chance to experience your service. Think about it this way: if you buy a T-shirt in an online store, you won't endorse it to anyone before you get it, right?
Targeted website surveys, mobile app surveys, or automated email flows will help you reach your respondents at the right time.
💡Real-life example: Taxify
Taxfix, a German mobile tax app, treats NPS data as the primary source of user insights. Surveys are triggered by specific events in the user journey—after a user files their tax declaration and after the tax office makes a tax refund.
But Taxfix also uses this data to personalize the app experience.
We ask three questions that help us classify our users and put them into one of our targeting groups. And then that information is also saved in Braze, our CRM tool, and the team uses that for content personalization.
Krzysztof Szymański, Head of CRM at TaxfixAnd it pays off, Taxfix's NPS score is a whooping 68, with an average completion rate around 80%.
5. Report and analyze to create benchmarks
Don't forget to report your results in an easily digestible way. Clear data breakdown will let you turn feedback into action. You'll create benchmarks, see results across customer segments, and prepare NPS-centric KPIs.
It's easy to do with the help of the right NPS tool—like Surivcate and the Insights Hub.
6. Solve the most common problems pointed out by detractors
Negative feedback means your client encountered friction with your service. It might happen in a product, on a website, or while talking with customer service.
Assign each piece of negative feedback to the right stage of the customer journey and purchase path. If you run a transactional NPS survey, check which experience scores the worst on average. You'll quickly discover your weakest points and will be able to fix them.
7. React to feedback in real-time
Don't ignore your detractors' negative feedback. Try to make up for your clients' bad experiences as soon as possible—you might prevent negative online reviews and bad word-of-mouth.
Survicate will make notifications and alerts easy for you—on Slack, for example.
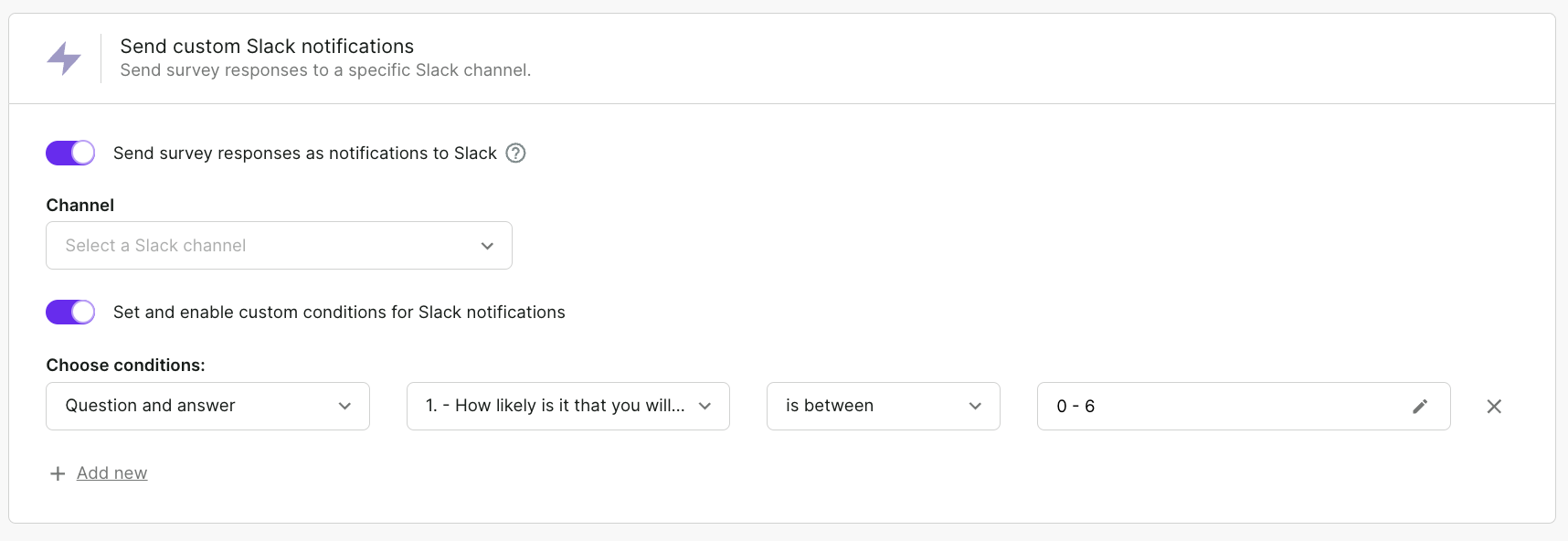
Whenever a low score appears, your customer support team will be able to react right away.
8. Use skip logic to ask relevant questions only
Your surveys must be as clear, short, and effortless to submit as possible.
With survey logic, you'll have complete control over which questions your respondents see. For example, there's no point in asking a detractor who chose “one” about their favorite part of your product.
Survicate NPS survey templates come with built-in logic.
9. Stay consistent and don't make many changes at once
Testing and tweaking your NPS survey will help you adjust it to your customers' needs and maximize the response rate.
But don't introduce too many changes at once! Go with one change at a time. It's the only way to ensure your results will be comparable over time.
10. Introduce NPS as a company-wide KPI
NPS relates to every interaction your customers have with your company. It reflects the overall health of your customer relationships. It should matter to every department.
Here's what you can do to share the NPS results across teams:
- Make it a core business metric. Use it as a growth signal and a motivator for your teams.
- Share relevant feedback with relevant teams. For example, if someone pointed out that they had a bad experience with your customer service, they should know and improve. That's the only way to close the feedback loop. If you use both Slack and Survicate, consider setting up an open NPS channel.
- Give all the teams access to the NPS results. They'll be able to find feedback that matters to them without waiting for a monthly marketing report. It's easy to do with Survicate, which offers free unlimited users on each account.
Summary
Net Promoter Score® (NPS) is a customer loyalty and satisfaction metric. It uses the following question: “How likely are you to recommend [company X] to a friend or colleague?” to gauge these KPIs.
The score lies on a scale from -100 to +100. To calculate NPS, you need to subtract the percentage of detractors from the percentage of promoters.
NPS is a company growth indicator. It helps predict how many customers will stay loyal to your brand and spread good word-of-mouth. And the more referrals and recurring customers you have, the better your bottom line.
Always add open-ended questions to your NPS surveys. Ask your clients to explain their decision: what they liked, disliked, and what you could improve to wow them. Addressing customer feedback will help you continue satisfying your audience over time.
Remember to measure NPS regularly. It will help you prepare benchmarks, set up NPS-related goals, and take action to improve customer satisfaction. Without accurate survey data analysis, you're shooting blanks.
The best way to measure NPS is with the help of the right survey tool, like Survicate. It will help you:
- quickly set up recurring, automatically triggered surveys (based on a ready-to-grab NPS survey template),
- gather and sum up your data,
- share all responses with your co-workers.
If you register right now, you can start gathering customer feedback in less than 10 minutes.













